고정 헤더 영역
상세 컨텐츠
본문
배열 Array
index와 그 index에 대응하는 데이터의 묶음
- list(파이썬): 가변적 시퀀스형, 동적 배열, 다른 타입의 자료형이 허용 된다.
- array: import 필요, 다른 타입의 자료형 입력 불가
import array as arr
mylist = [1, 2, 3] # 이것은 파이썬 built-in list입니다.
print(type(mylist))
mylist.append('4') # mylist의 끝에 character '4'를 추가합니다.
print(mylist)
mylist.insert(1, 5) # mylist의 두번째 자리에 5를 끼워넣습니다.
print(mylist)숫자형으로만 이루어진 mylist에 문자열 '4'를 추가할 수 있다.
myarray = arr.array('i', [1, 2, 3]) # 이것은 array입니다. import array를 해야 쓸 수 있습니다.
print(type(myarray))
# 아래 라인을실행하면 에러가 납니다.
myarray.append('4') # myarray의 끝에 character '4'를 추가합니다.
print(myarray)>> TypeError: an integer is required (got type str)array는 처음부터 인자의 타입을 지정해서 생성하고, 지정된 타입 외의 인자는 받지 않는다.
타입 코드: 정수 = 'i' , 실수 = 'd'
따라서 정수로 인자의 유형을 정한 myarray에 문자열인 '4'를 추가하려고 하면 오류가 난다.
myarray.insert(1, 5) # myarray의 두번째 자리에 5를 끼워넣습니다.
print(myarray)정수 인자인 5는 삽입이 가능하다.
1) array: array는 입력된 인자를 연속된 메모리 공간에 저장한다. 따라서 인덱스를 활용한 직접 접근이 용이하다. (myarray[2] 과 같이 배열 속 인자에 빠르게 접근 가능) 대신에 인자의 추가와 삭제는 용이하지 않다.
2) list: 반면 list는 인자를 연속된 위치가 아닌 떨어진 영역에 저장한다. 대신에 인자와 함께 다음 인자를 지목하는 pointer를 함께 저장한다. (마치 like 보물찾기) 인자의 추가와 삭제 시 pointer 정보만 바꾸면 되기 때문에 상대적으로 쉽다.
📍 파이썬 list는 array와 list의 특징을 모두 가지고 있음
______________________________________________________________________________________________________________________________________Numpy
Numerical Python. 대규모 다차원 배열을 쉽게 처리할 수 있도록 지원하는 파이썬 패키지
- ndarray 객체: NumPy가 지원하는 다차원 배열, NumPy는
ndarray를 기준으로 선형대수 연산이 필요한 알고리즘에 쓰인다.
1) ndarray 만들기
arange()와 array([])로 만들 수 있음.
import numpy as np
# 아래 A와 B는 결과적으로 같은 ndarray 객체를 생성합니다.
A = np.arange(5)
B = np.array([0,1,2,3,4]) # 파이썬 리스트를 numpy ndarray로 변환
# 하지만 C는 좀 다를 것입니다.
C = np.array([0,1,2,3,'4'])
# D도 A, B와 같은 결과를 내겠지만, B의 방법을 권합니다.
D = np.ndarray((5,), np.int64, np.array([0,1,2,3,4]))
print(A)
print(type(A))
print("--------------------------")
print(B)
print(type(B))
print("--------------------------")
print(C)
print(type(C))
print("--------------------------")
print(D)
print(type(D))[0 1 2 3 4]
<class 'numpy.ndarray'>
--------------------------
[0 1 2 3 4]
<class 'numpy.ndarray'>
--------------------------
['0' '1' '2' '3' '4']
<class 'numpy.ndarray'>
--------------------------
[0 1 2 3 4]
<class 'numpy.ndarray'>C의 경우는 문자열인 4가 하나 들어가니 모든 인자들이 문자열로 바뀌었음. (데이터 타입이 일정해야 하기 때문에)
2) 크기 (size, shape, ndim)
ndarray.size: 행렬 내 원소의 개수ndarray.shape: 행렬의 모양ndarray.ndim: 행렬의 axis 개수
reshape() 함수를 이용해서 행렬의 모양을 바꿀 수 있는데, 대신 바꾸기 전 후 행렬의 size가 같아야 한다
예) 1x10 행렬 => 2x5 행렬 O / 1x10 행렬 => 3x3 행렬 X
3) type
NumPy와 Python 내장함수는 거의 동일. 다만 type()과 dtype()이 다르다.
NumPy:
numpy.array.dtype파이썬:
type()
A = np.array([0, 1, 2, 3, 4, 5])
print(A.dtype)
>> int64👉 ndarray 원소의 데이터 타입을 반환
print(type(A))
>> <class 'numpy.ndarray`>👉 A의 클래스인 numpy.ndarray 반환
4) 특수 행렬
단위행렬:
np.eye()0 행렬:
np.zeros()1 행렬:
np.ones()
5) Broadcast 연산
'broadcast': 흩뿌리고 퍼뜨리고 전파하다.
원래는 다른 모양의 배열끼리는 연산이 안되지만 특정 조건이 맞으면 모양이 다른 배열끼리도 연산할 수 있게 해주는 기능.
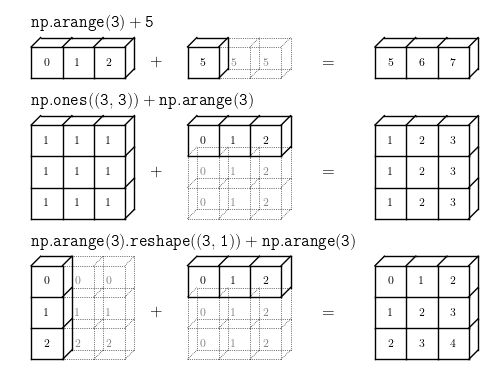
👉 파이썬 내장 list 와 구별되는 Numpy의 큰 특징
6) 슬라이스와 인덱싱
인덱싱: np.ndarray[행,열]
슬라이싱: np.ndarray[:n행까지,:n열까지]
인덱싱과 슬라이싱의 혼합도 가능 예) A[:, -1]
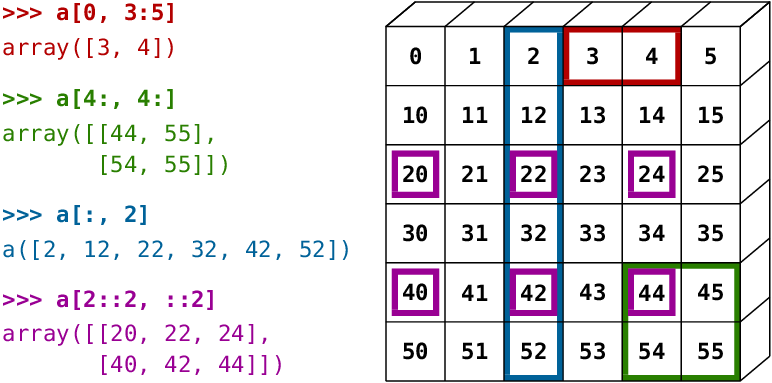
7) np.random
- np.random.randint()
- np.random.choice()
- np.random.permutation()
- np.random.normal()
- np.random.uniform()
8) 전치행렬
arr.T: 행렬의 행과 열 맞바꾸기
np.transpose: 축을 기준으로 행렬의 행과 열 바꾸기 (축을 지정해 줘야 함)
기본 통계 연산
- np.sum()
- np.mean()
- np.std()
- np.median(np)
import numpy as np
def numbers():
X = []
number = input("Enter a number (<Enter key> to quit)")
# 하지만 2개 이상의 숫자를 받아야 한다는 제약조건을 제외하였습니다.
while number != "":
try:
x = float(number)
X.append(x)
except ValueError:
print('>>> NOT a number! Ignored..')
number = input("Enter a number (<Enter key> to quit)")
return X
def main():
nums = numbers() # 이것은 파이썬 리스트입니다.
num = np.array(nums) # 리스트를 Numpy ndarray로 변환합니다.
print("합", num.sum())
print("평균값",num.mean())
print("표준편차",num.std())
print("중앙값",np.median(num)) # num.median() 이 아님에 유의해 주세요.
main()이미지의 행렬 변환
A Visual Intro to Numpy and Data Representaion
소리 데이터, 흑백/컬러 이미지, 자연어 모두 NumPy를 이용해 배열로 표현한다.
그 중 이미지는 수많은 픽셀로 이루어져 있는데, 각 픽셀마다 튜플로 색상을 표시한다.

'AIFFEL👩🏻💻' 카테고리의 다른 글
| 탐색적 데이터 분석(EDA) (0) | 2022.01.21 |
|---|---|
| [EXPLORATION 4] 작사가 인공지능 만들기 (0) | 2022.01.13 |
| [Exploration 3] 카메라 스티커앱 만들기 첫걸음 (0) | 2022.01.11 |




